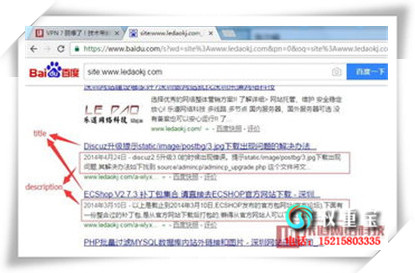
南阳SEO优化将网站关键词排名推广到百度快照第1页
152-1580-3335
网站推广、网站建设专家!
专业、务实、高效
网站推广、网站建设专家!
专业、务实、高效
网站SEO跟踪 细看robots.txt划定规矩的实践结果
10月20日,我对专客停止了年夜范围调解,便好像看待亟待生长的树普通建枝剪叶,以期能有较好的生长趋向。此中robots.txt被我充实的操纵起去。
现在一个事情周行将已往,robots.txt文件划定规矩能否准确,能否曾经死效?百度谷歌等搜素引擎能否呼应了robots.txt划定规矩停止索引调解?做为站少我需求深化研讨一番,以便静态把握专客支录形态。
经查询拜访发明,谷歌对robots.txt反响比力疾速,第三天正在网站办理东西里找到了迹象。百度表示没有尽善尽美,道百度没有认robots.txt划定规矩那是瞎扯,但反响周期云云之少,不免会留下反响缓没有做为的猜忌。
看谷歌对robots.txt划定规矩之反响
正在20日做的调解中,有两条划定规矩我厥后做了删除。翻开我专客的robots.txt,战20日停止调解写下的比照,可知此中变革。
做此调解的本果正在于,如根据20日的写法,第两天我发明,网站办理员东西Sitemaps里三个被选中的地点前呈现了叉号——被robots.txt文件划定规矩给阻遏了——那个出须要嘛。其时的截图找没有到了,上面三个选中的能够看一下:
提交的sitemap网站舆图
呼应robots.txt划定规矩,谷歌截至了2000 多个毗连地点的抓与。那500多个找没有到地点,是果为前段工夫删除文章标签tags后遗症。上面是截图:
2000多个毗连地点被robots.txt划定规矩限定
翻遍每页,出有发明成绩——除一些/?p=的短毗连让民气痛中,统统完善得空。严厉去道,该当是robots.txt划定规矩没有存正在成绩,谷歌没有合没有扣的施行了robots.txt划定规矩。
谷歌查询“site:*** inurl:?p” 仅找到残破的14条(无题目或戴要)。没有暂的未来那些地点将被肃清。
看百度对robots.txt划定规矩之反响
20日便有robots.txt文件划定规矩了,那是甚么状况?
划定规矩20日造定,上里那图没有知是脱越了,借是我目炫了?我查过IIS日记记载,百度20往后曾屡次下载robot.txt文件,效劳器返回的是200胜利形态码。
易怪百度没有招列位站少待睹。
百度“敬爱的站少,我是您爹”高屋建瓴的立场,能否该当改变一下了?
本文地点:没有得行专客
注:相干网站建立本领浏览请移步到建站教程频讲。

相关信息
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|